Node.js 基础
运行原理
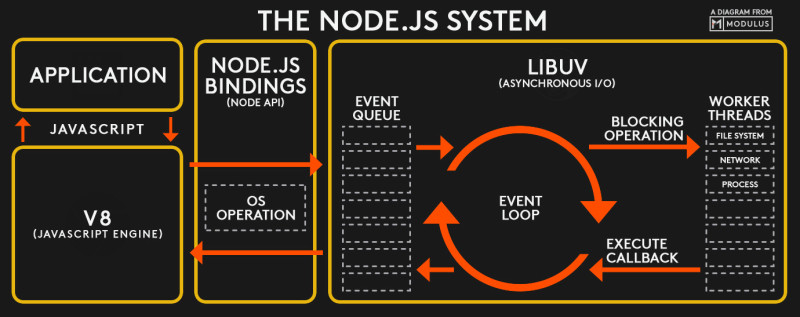
- 一般来说,不同语言之间的规范不同,所以写出来的代码无法直接沟通,这时候就需要Bindings层,它是一些胶水代码,能够把不同的语言绑定在一起使其能够相互沟通。
- 在Node.js中,Bindings层所做的就是把底层的C/C++接口暴露给JavaScript环境,从而打通JavaScript与C/C++之间的相互调用。
- libuv是提供异步功能的C库。它在运行时负责一个事件循环(Event Loop)、一个线程池、文件系统I/O、DNS相关的I/O和网络I/O,以及一些其他重要功能。
REPL
_代表最后一次操作的结果
REPL 有一些特殊的命令,所有这些命令都以点号 . 开头:
.help: 显示点命令的帮助。.editor: 启用编辑器模式,可以轻松地编写多行 JavaScript 代码。当处于此模式时,按下 ctrl-D 可以运行编写的代码。.break: 当输入多行的表达式时,输入.break命令可以中止进一步的输入。相当于按下 ctrl-C。.clear: 将 REPL 上下文重置为空对象,并清除当前正在输入的任何多行的表达式。.load: 加载 JavaScript 文件(相对于当前工作目录)。.save: 将在 REPL 会话中输入的所有内容保存到文件(需指定文件名)。.exit: 退出 REPL(相当于按下两次 ctrl-C)。
如果 REPL 能判断出是否正在输入多行的语句,则无需调用 .editor。
异步I/O
- 为了弥补单线程无法利用多核CPU的缺点,Node提供了类似前端浏览器中Web Workers的子进程,该子进程可以通过工作进程高效地利用CPU和I/O。
操作系统内核对于I/O只有两种方式:阻塞与非阻塞。
非阻塞I/O跟阻塞I/O的差别为调用之后会立即返回
-
在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们称为Tick。
-
每个Tick的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。
- 事实上,在Node中,除了JavaScript是单线程外,Node自身其实是多线程的,只是I/O线程使用的CPU较少。另一个需要重视的观点则是,除了用户代码无法并行执行外,所有的I/O(磁盘I/O和网络I/O等)则是可以并行起来的。
- 每次调用process.nextTick()方法,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的操作时间复杂度为O(lg(n)), nextTick()的时间复杂度为O(1)。相较之下,process.nextTick()更高效。
路径操作
path是 Node 本身提供的一个核心模块,专门用来处理路径。 可移植操作系统接口(Portable Operating System Interface: POSIX) Linux和MacOS支持POSIX Windows部分支持(win10下的WSL强制实现)
path.basename()
path.basename("/foo/bar/baz/asdf/quux.html");
// Returns: 'quux.html'
path.basename("/foo/bar/baz/asdf/quux.html", ".html");
// Returns: 'quux'
path.dirname()
path.extname()
path.extname("index.html");
// Returns: '.html'
path.extname("index.coffee.md");
// Returns: '.md'
path.extname("index.");
// Returns: '.'
path.extname("index");
// Returns: ''
path.extname(".index");
// Returns: ''
path.parse()
path.parse("/home/user/dir/file.txt");
// Returns:
// { root: '/',
// dir: '/home/user/dir',
// base: 'file.txt',
// ext: '.txt',
// name: 'file' }
path.format(pathObject)
// If `dir`, `root` and `base` are provided,
// `${dir}${path.sep}${base}`
// will be returned. `root` is ignored.
path.format({
root: "/ignored",
dir: "/home/user/dir",
base: "file.txt"
});
// Returns: '/home/user/dir/file.txt'
// `root` will be used if `dir` is not specified.
// If only `root` is provided or `dir` is equal to `root` then the
// platform separator will not be included. `ext` will be ignored.
path.format({
root: "/",
base: "file.txt",
ext: "ignored"
});
// Returns: '/file.txt'
// `name` + `ext` will be used if `base` is not specified.
path.format({
root: "/",
name: "file",
ext: ".txt"
});
// Returns: '/file.txt'
path.join()
path.join("/foo", "bar", "baz/asdf", "quux", "..");
// Returns: '/foo/bar/baz/asdf'
path.join("foo", {}, "bar");
// throws 'TypeError: Path must be a string. Received {}'
path.isAbsolute()
// *nix
path.isAbsolute("/foo/bar"); // true
path.isAbsolute("/baz/.."); // true
path.isAbsolute("qux/"); // false
path.isAbsolute("."); // false
// Windows
path.isAbsolute("//server"); // true
path.isAbsolute("\\\\server"); // true
path.isAbsolute("C:/foo/.."); // true
path.isAbsolute("C:\\foo\\.."); // true
path.isAbsolute("bar\\baz"); // false
path.isAbsolute("bar/baz"); // false
path.isAbsolute("."); // false
path.normalize()
path.normalize("/foo/bar//baz/asdf/quux/..");
// Returns: '/foo/bar/baz/asdf'
path.normalize("C:\\temp\\\\foo\\bar\\..\\");
// Returns: 'C:\\temp\\foo\\'
path.resolve([...paths])
path.resolve()方法将路径或路径片段的序列解析为绝对路径
给定的路径序列从右到左处理,每个后续的 path 会被追加到前面,直到构建绝对路径
如果在处理完所有给定的 path 片段之后,还没有生成绝对路径,则使用当前工作目录
path.resolve('/foo/bar', './baz');
// Returns: '/foo/bar/baz'
path.resolve('/foo/bar', '/tmp/file/');
// Returns: '/tmp/file'
path.resolve('wwwroot', 'static_files/png/', '../gif/image.gif');
// If the current working directory is /home/myself/node,
// this returns '/home/myself/node/wwwroot/static_files/gif/image.gif'
process
process不需要require,它是自动可用的
查看PATH
设置PATH
获取信息
// 获取平台信息
process.arch // x64
process.platform // darwin
// 获取内存使用情况
process.memoryUsage();
// 获取命令行参数,返回值是一个数组
// 0: Node路径
// 1: 被执行的JS文件路径
// 2~n: 真实传入的参数
process.argv // argv是argument vector的缩写
const args = process.argv.slice(2);
// 获取当前进程的执行目录
process.cwd()
// 环境变量
process.env
nextTick
process.nextTick方法允许把一个回调放在下一次时间轮询队列的头上,这意味着可以用来延迟执行,结果是比setTimeout更有效率
const EventEmitter = require('events').EventEmitter;
function complexOperations() {
const events = new EventEmitter();
process.nextTick(function () {
events.emit('success');
});
return events;
}
complexOperations().on('success', function () {
console.log('success!');
});
退出程序
Buffer
Buffer 是内存区域,它表示在 V8 JavaScript 引擎外部分配的固定大小的内存块(无法调整大小)
可以将 buffer 视为整数数组,每个整数代表一个数据字节
如果没有提供编码格式,文件操作以及很多网络操作就会将数据作为 Buffer 类型返回
为什么需要buffer?
Buffer 被引入用以帮助开发者处理二进制数据,在此生态系统中传统上只处理字符串而不是二进制数据
Buffer 与流紧密相连, 当流处理器接收数据的速度快于其消化的速度时,则会将数据放入 buffer 中
创建
使用 Buffer.from()、Buffer.alloc() 和 Buffer.allocUnsafe() 方法可以创建 buffer。
Buffer.from(array)Buffer.from(arrayBuffer[, byteOffset[, length\]])Buffer.from(buffer)Buffer.from(string[, encoding\])
也可以只初始化 buffer(传入大小)。 以下会创建一个 1KB 的 buffer:
虽然 alloc 和 allocUnsafe 均分配指定大小的 Buffer(以字节为单位),但是 alloc 创建的 Buffer 会被使用零进行初始化,而 allocUnsafe 创建的 Buffer 不会被初始化。 这意味着,尽管 allocUnsafe 比 alloc 要快得多,但是分配的内存片段可能包含可能敏感的旧数据。
当 Buffer 内存被读取时,如果内存中存在较旧的数据,则可以被访问或泄漏。 这就是真正使 allocUnsafe 不安全的原因,在使用它时必须格外小心。
使用
Buffer(字节数组)可以像数组一样被访问:
const buf = Buffer.from('Hey!')
console.log(buf[0]) //72
console.log(buf[1]) //101
console.log(buf[2]) //121
这些数字是 Unicode 码,用于标识 buffer 位置中的字符(H => 72、e => 101、y => 121)。
可以使用 toString() 方法打印 buffer 的全部内容:
默认转为 UTF-8 格式,还支持 ascii、base64 等
获取 buffer 的长度
使用 length 属性:
迭代 buffer 的内容
更改 buffer 的内容
可以使用 write() 方法将整个数据字符串写入 buffer:
就像可以使用数组语法访问 buffer 一样,你也可以使用相同的方式设置 buffer 的内容:
复制 buffer
使用 copy() 方法可以复制 buffer:
默认情况下,会复制整个 buffer。 另外的 3 个参数可以定义开始位置、结束位置、以及新的 buffer 长度:
const buf = Buffer.from('Hey!')
let bufcopy = Buffer.alloc(2) //分配 2 个字节。
buf.copy(bufcopy, 0, 0, 2)
bufcopy.toString() //'He'
切片 buffer
如果要创建 buffer 的局部视图,则可以创建切片。 切片不是副本:原始 buffer 仍然是真正的来源。 如果那改变了,则切片也会改变。
使用 slice() 方法创建它。 第一个参数是起始位置,可以指定第二个参数作为结束位置:
const buf = Buffer.from('Hey!')
buf.slice(0).toString() //Hey!
const slice = buf.slice(0, 2)
console.log(slice.toString()) //He
buf[1] = 111 //o
console.log(slice.toString()) //Ho
data URI
// 生成 data URI
const fs = require('fs');
const mime = 'image/png';
const encoding = 'base64';
const base64Data = fs.readFileSync(`${__dirname}/monkey.png`).toString(encoding);
const uri = `data:${mime};${encoding},${base64Data}`;
console.log(uri);
// data URI 转文件
const fs = require('fs');
const uri = 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgA...';
const base64Data = uri.split(',')[1];
const buf = Buffer(base64Data, 'base64');
fs.writeFileSync(`${__dirname}/secondmonkey.png`, buf);
events
events模块提供了EventEmitter类用于处理事件
EventEmitter 的常用方法:
addListener():on()的别名emit():触发事件,按照事件被注册的顺序同步的调用每个事件监听器eventNames():返回字符串(表示在当前EventEmitter对象上注册的事件)数组getMaxListeners():获取可以添加到EventEmitter对象的监听器的最大数量(默认为 10,但可以使用setMaxListeners()进行增加或减少)listenerCount():获取作为参数传入的事件监听器的计数listeners():获取作为参数传入的事件监听器的数组off():removeListener()的别名on():添加当事件被触发时调用的回调函数once(): 添加当事件在注册之后首次被触发时调用的回调函数。 该回调只会被调用一次,不会再被调用prependListener():当使用on或addListener添加监听器时,监听器会被添加到监听器队列中的最后一个,并且最后一个被调用。 使用prependListener则可以在其他监听器之前添加并调用prependOnceListener():当使用once添加监听器时,监听器会被添加到监听器队列中的最后一个,并且最后一个被调用。 使用prependOnceListener则可以在其他监听器之前添加并调用removeListener(): 从事件中移除事件监听器removeAllListeners(): 移除事件的所有监听器setMaxListeners():设置可以添加到EventEmitter对象的监听器的最大数量(默认为 10,但可以增加或减少)
一个播放器的实例:
const EventEmitter = require('events').EventEmitter;
const AudioDevice = {
play: function (track) {
console.log('play', track);
},
stop: function () {
console.log('stop');
},
};
class MusicPlayer extends EventEmitter {
constructor() {
super();
this.playing = false;
}
}
const musicPlayer = new MusicPlayer();
musicPlayer.on('play', function (track) {
this.playing = true;
AudioDevice.play(track);
});
musicPlayer.on('stop', function () {
this.playing = false;
AudioDevice.stop();
});
musicPlayer.emit('play', 'The Roots - The Fire');
setTimeout(function () {
musicPlayer.emit('stop');
}, 1000);
// 处理异常
// EventEmitter 实例发生错误会发出一个 error 事件
// 如果没有监听器,默认动作是打印一个堆栈并退出程序
musicPlayer.on('error', function (err) {
console.err('Error:', err);
});
util
promisify
const util = require('util');
const fs = require('fs');
const readAsync = util.promisify(fs.readFile);
async function init() {
try {
let data = await readAsync('./package.json');
data = JSON.parse(data);
console.log(data.name);
} catch (err) {
console.log(err);
}
}
流
理解流
流是基于事件的 API,用于管理和处理数据。
- 流是能够读写的
- 是基于事件实现的一个实例
流的优点:
- 内存效率: 无需加载大量的数据到内存中即可进行处理。
- 时间效率: 当获得数据之后即可立即开始处理数据,这样所需的时间更少,而不必等到整个数据有效负载可用才开始
流的类型
- 内置:许多核心模块都实现了流接口,如
fs.createReadStream - HTTP:处理网络技术的流
- 解释器:第三方模块 XML、JSON 解释器
- 浏览器:Node 流可以被拓展使用在浏览器
- Audio:流接口的声音模块
- RPC(远程调用):通过网络发送流是进程间通信的有效方式
- 测试:使用流的测试库
使用内建流 API
静态 web 服务器
想要通过网络高效且支持大文件的发送一个文件到一个客户端。
不使用流
const http = require('http');
const fs = require('fs');
http.createServer((req, res) => {
fs.readFile(`${__dirname}/index.html`, (err, data) => {
if (err) {
res.statusCode = 500;
res.end(String(err));
return;
}
res.end(data);
});
}).listen(8000);
使用流
const http = require('http');
const fs = require('fs');
http.createServer((req, res) => {
fs.createReadStream(`${__dirname}/index.html`).pipe(res);
}).listen(8000);
- 更少代码,更加高效
- 提供一个缓冲区发送到客户端
使用流 + gzip
const http = require('http');
const fs = require('fs');
const zlib = require('zlib');
http.createServer((req, res) => {
res.writeHead(200, {
'content-encoding': 'gzip',
});
fs.createReadStream(`${__dirname}/index.html`)
.pipe(zlib.createGzip())
.pipe(res);
}).listen(8000);
流的错误处理
const fs = require('fs');
const stream = fs.createReadStream('not-found');
stream.on('error', (err) => {
console.trace();
console.error('Stack:', err.stack);
console.error('The error raised was:', err);
});
使用流基类
可读流 - JSON 行解析器
可读流被用来为 I/O 源提供灵活的 API,也可以被用作解析器:
- 继承自 steam.Readable 类
- 并实现一个
_read(size)方法
json-lines.txt
{ "position": 0, "letter": "a" }
{ "position": 1, "letter": "b" }
{ "position": 2, "letter": "c" }
{ "position": 3, "letter": "d" }
{ "position": 4, "letter": "e" }
{ "position": 5, "letter": "f" }
{ "position": 6, "letter": "g" }
{ "position": 7, "letter": "h" }
{ "position": 8, "letter": "i" }
{ "position": 9, "letter": "j" }
JSONLineReader.js
const stream = require('stream');
const fs = require('fs');
const util = require('util');
class JSONLineReader extends stream.Readable {
constructor(source) {
super();
this._source = source;
this._foundLineEnd = false;
this._buffer = '';
source.on('readable', () => {
this.read();
});
}
// 所有定制 stream.Readable 类都需要实现 _read 方法
_read(size) {
let chunk;
let line;
let result;
if (this._buffer.length === 0) {
chunk = this._source.read();
this._buffer += chunk;
}
const lineIndex = this._buffer.indexOf('\n');
if (lineIndex !== -1) {
line = this._buffer.slice(0, lineIndex); // 从 buffer 的开始截取第一行来获取一些文本进行解析
if (line) {
result = JSON.parse(line);
this._buffer = this._buffer.slice(lineIndex + 1);
this.emit('object', result); // 当一个 JSON 记录解析出来的时候,触发一个 object 事件
this.push(util.inspect(result)); // 将解析好的 SJON 发回内部队列
} else {
this._buffer = this._buffer.slice(1);
}
}
}
}
const input = fs.createReadStream(`${__dirname}/json-lines.txt`, {
encoding: 'utf8',
});
const jsonLineReader = new JSONLineReader(input); // 创建一个 JSONLineReader 实例,传递一个文件流给它处理
jsonLineReader.on('object', (obj) => {
console.log('pos:', obj.position, '- letter:', obj.letter);
});
可写流 - 文字变色
可写的流可用于输出数据到底层 I/O:
- 继承自
stream.Writable - 实现一个
_write方法向底层源数据发送数据
stram_writable.js
const stream = require('stream');
class GreenStream extends stream.Writable {
constructor(options) {
super(options);
}
_write(chunk, encoding, cb) {
process.stdout.write(`\u001b[32m${chunk}\u001b[39m`);
cb();
}
}
process.stdin.pipe(new GreenStream());
双工流 - 接受和转换数据
双工流允许发送和接受数据:
- 继承自
stream.Duplex - 实现
_read和_write方法
转换流 - 解析数据
使用流改变数据为另一种格式,并且高效地管理内存:
- 继承自
stream.Transform - 实现
_transform方法
测试流
使用 Node 内置的断言模块测试
const assert = require('assert');
const fs = require('fs');
const CSVParser = require('./csvparser');
const parser = new CSVParser();
const actual = [];
fs.createReadStream(`${__dirname}/sample.csv`)
.pipe(parser);
process.on('exit', function () {
actual.push(parser.read());
actual.push(parser.read());
actual.push(parser.read());
const expected = [
{ name: 'Alex', location: 'UK', role: 'admin' },
{ name: 'Sam', location: 'France', role: 'user' },
{ name: 'John', location: 'Canada', role: 'user' },
];
assert.deepEqual(expected, actual);
});
文件系统
fs 模块交互
- POSIX 文件 I/O
- 文件流
- 批量文件 I/O
- 文件监控
POSIX 文件系统
| fs 方法 | 描述 |
|---|---|
| fs.truncate | 截断或者拓展文件到制定的长度 |
| fs.ftruncate | 和 truncate 一样,但将文件描述符作为参数 |
| fs.chown | 改变文件的所有者以及组 |
| fs.fchown | 和 chown 一样,但将文件描述符作为参数 |
| fs.lchown | 和 chown 一样,但不解析符号链接 |
| fs.stat | 获取文件状态 |
| fs.lstat | 和 stat 一样,但是返回信息是关于符号链接而不是它指向的内容 |
| fs.fstat | 和 stat 一样,但将文件描述符作为参数 |
| fs.link | 创建一个硬链接 |
| fs.symlink | 创建一个软连接 |
| fs.readlink | 读取一个软连接的值 |
| fs.realpath | 返回规范的绝对路径名 |
| fs.unlink | 删除文件 |
| fs.rmdir | 删除文件目录 |
| fs.mkdir | 创建文件目录 |
| fs.readdir | 读取一个文件目录的内容 |
| fs.close | 关闭一个文件描述符 |
| fs.open | 打开或者创建一个文件用来读取或者写入 |
| fs.utimes | 设置文件的读取和修改时间 |
| fs.futimes | 和 utimes 一样,但将文件描述符作为参数 |
| fs.fsync | 同步磁盘中的文件数据 |
| fs.write | 写入数据到一个文件 |
| fs.read | 读取一个文件的数据 |
const fs = require('fs');
const assert = require('assert');
const fd = fs.openSync('./file.txt', 'w+');
const writeBuf = new Buffer('some data to write');
fs.writeSync(fd, writeBuf, 0, writeBuf.length, 0);
const readBuf = new Buffer(writeBuf.length);
fs.readSync(fd, readBuf, 0, writeBuf.length, 0);
assert.equal(writeBuf.toString(), readBuf.toString());
fs.closeSync(fd);
读写流
const fs = require('fs');
const readable = fs.createReadStream('./original.txt');
const writeable = fs.createWriteStream('./copy.txt');
readable.pipe(writeable);
文件监控
fs.watchFile 比 fs.watch 低效,但更好用。
同步读取与 require
同步 fs 的方法应该在第一次初始化应用的时候使用。
const fs = require('fs');
const config = JSON.parse(fs.readFileSync('./config.json').toString());
init(config);
require:
- 模块会被全局缓冲,其他文件也加载并修改,会影响到整个系统加载了此文件的模块
- 可以通过
Object.freeze来冻结一个对象
文件描述
文件描述是在操作系统中管理的在进程中打开文件所关联的一些数字或者索引。操作系统通过指派一个唯一的整数给每个打开的文件用来查看关于这个文件
| Stream | 文件描述 | 描述 |
|---|---|---|
| stdin | 0 | 标准输入 |
| stdout | 1 | 标准输出 |
| stderr | 2 | 标准错误 |
console.log('Log') 是 process.stdout.write('log') 的语法糖。
一个文件描述是 open 以及 openSync 方法调用返回的一个数字
文件锁
协同多个进程同时访问一个文件,保证文件的完整性以及数据不能丢失:
- 强制锁(在内核级别执行)
- 咨询锁(非强制,只在涉及到进程订阅了相同的锁机制)
node-fs-ext通过flock锁住一个文件- 使用锁文件
- 进程 A 尝试创建一个锁文件,并且成功了
- 进程 A 已经获得了这个锁,可以修改共享的资源
- 进程 B 尝试创建一个锁文件,但失败了,无法修改共享的资源
Node 实现锁文件
- 使用独占标记创建锁文件
- 使用 mkdir 创建锁文件
独占标记
// 所有需要打开文件的方法,fs.writeFile、fs.createWriteStream、fs.open 都有一个 x 标记
// 这个文件应该已独占打开,若这个文件存在,文件不能被打开
fs.open('config.lock', 'wx', (err) => {
if (err) { return console.err(err); }
});
// 最好将当前进程号写进文件锁中
// 当有异常的时候就知道最后这个锁的进程
fs.writeFile(
'config.lock',
process.pid,
{ flogs: 'wx' },
(err) => {
if (err) { return console.error(err) };
},
);
mkdir 文件锁
独占标记有个问题,可能有些系统不能识别 0_EXCL 标记。另一个方案是把锁文件换成一个目录,PID 可以写入目录中的一个文件。
fs.mkidr('config.lock', (err) => {
if (err) { return console.error(err); }
fs.writeFile(`/config.lock/${process.pid}`, (err) => {
if (err) { return console.error(err); }
});
});
lock 模块实现
https://github.com/npm/lockfile
const fs = require('fs');
const lockDir = 'config.lock';
let hasLock = false;
exports.lock = function (cb) { // 获取锁
if (hasLock) { return cb(); } // 已经获取了一个锁
fs.mkdir(lockDir, function (err) {
if (err) { return cb(err); } // 无法创建锁
fs.writeFile(lockDir + '/' + process.pid, function (err) { // 把 PID写入到目录中以便调试
if (err) { console.error(err); } // 无法写入 PID,继续运行
hasLock = true; // 锁创建了
return cb();
});
});
};
exports.unlock = function (cb) { // 解锁方法
if (!hasLock) { return cb(); } // 如果没有需要解开的锁
fs.unlink(lockDir + '/' + process.pid, function (err) {
if (err) { return cb(err); }
fs.rmdir(lockDir, function (err) {
if (err) return cb(err);
hasLock = false;
cb();
});
});
};
process.on('exit', function () {
if (hasLock) {
fs.unlinkSync(lockDir + '/' + process.pid); // 如果还有锁,在退出之前同步删除掉
fs.rmdirSync(lockDir);
console.log('removed lock');
}
});
递归文件操作
一个线上库:mkdirp
dir-a
├── dir-b
│ ├── dir-c
│ │ ├── dir-d
│ │ │ └── file-e.png
│ │ └── file-e.png
│ ├── file-c.js
│ └── file-d.txt
├── file-a.js
└── file-b.txt
查找模块:find /asset/dir-a -name="file.*"
[
'dir-a/dir-b/dir-c/dir-d/file-e.png',
'dir-a/dir-b/dir-c/file-e.png',
'dir-a/dir-b/file-c.js',
'dir-a/dir-b/file-d.txt',
'dir-a/file-a.js',
'dir-a/file-b.txt',
]
const fs = require('fs');
const join = require('path').join;
// 同步查找
exports.findSync = function (nameRe, startPath) {
const results = [];
function finder(path) {
const files = fs.readdirSync(path);
for (let i = 0; i < files.length; i++) {
const fpath = join(path, files[i]);
const stats = fs.statSync(fpath);
if (stats.isDirectory()) { finder(fpath); }
if (stats.isFile() && nameRe.test(files[i])) {
results.push(fpath);
}
}
}
finder(startPath);
return results;
};
// 异步查找
exports.find = function (nameRe, startPath, cb) { // cb 可以传入 console.log,灵活
const results = [];
let asyncOps = 0; // 2
function finder(path) {
asyncOps++;
fs.readdir(path, function (er, files) {
if (er) { return cb(er); }
files.forEach(function (file) {
const fpath = join(path, file);
asyncOps++;
fs.stat(fpath, function (er, stats) {
if (er) { return cb(er); }
if (stats.isDirectory()) finder(fpath);
if (stats.isFile() && nameRe.test(file)) {
results.push(fpath);
}
asyncOps--;
if (asyncOps == 0) {
cb(null, results);
}
});
});
asyncOps--;
if (asyncOps == 0) {
cb(null, results);
}
});
}
finder(startPath);
};
console.log(exports.findSync(/file.*/, `${__dirname}/dir-a`));
console.log(exports.find(/file.*/, `${__dirname}/dir-a`, console.log));
监视文件和文件夹
想要监听一个文件或者目录,并在文件更改后执行一个动作。
const fs = require('fs');
fs.watch('./watchdir', console.log); // 稳定且快
fs.watchFile('./watchdir', console.log); // 跨平台
逐行地读取文件流
const fs = require('fs');
const readline = require('readline');
const rl = readline.createInterface({
input: fs.createReadStream('/etc/hosts'),
crlfDelay: Infinity
});
rl.on('line', (line) => {
console.log(`cc ${line}`);
const extract = line.match(/(\d+\.\d+\.\d+\.\d+) (.*)/);
});
网络
获取本地 IP
function get_local_ip() {
const interfaces = require('os').networkInterfaces();
let IPAdress = '';
for (const devName in interfaces) {
const iface = interfaces[devName];
for (let i = 0; i < iface.length; i++) {
const alias = iface[i];
if (alias.family === 'IPv4' && alias.address !== '127.0.0.1' && !alias.internal) {
IPAdress = alias.address;
}
}
}
return IPAdress;
}
TCP 客户端
NodeJS 使用 net 模块创建 TCP 连接和服务。
启动与测试 TCP
const assert = require('assert');
const net = require('net');
let clients = 0;
let expectedAssertions = 2;
const server = net.createServer(function (client) {
clients++;
const clientId = clients;
console.log('Client connected:', clientId);
client.on('end', function () {
console.log('Client disconnected:', clientId);
});
client.write('Welcome client: ' + clientId);
client.pipe(client);
});
server.listen(8000, function () {
console.log('Server started on port 8000');
runTest(1, function () {
runTest(2, function () {
console.log('Tests finished');
assert.equal(0, expectedAssertions);
server.close();
});
});
});
function runTest(expectedId, done) {
const client = net.connect(8000);
client.on('data', function (data) {
const expected = 'Welcome client: ' + expectedId;
assert.equal(data.toString(), expected);
expectedAssertions--;
client.end();
});
client.on('end', done);
}
UDP 客户端
利用 dgram 模块创建数据报 socket,然后利用 socket.send 发送数据。
文件发送服务
const dgram = require('dgram');
const fs = require('fs');
const port = 41230;
const defaultSize = 16;
function Client(remoteIP) {
const inStream = fs.createReadStream(__filename); // 从当前文件创建可读流
const socket = dgram.createSocket('udp4'); // 创建新的数据流 socket 作为客户端
inStream.on('readable', function () {
sendData(); // 当可读流准备好,开始发送数据到服务器
});
function sendData() {
const message = inStream.read(defaultSize); // 读取数据块
if (!message) {
return socket.unref(); // 客户端完成任务后,使用 unref 安全关闭它
}
// 发送数据到服务器
socket.send(message, 0, message.length, port, remoteIP, function () {
sendData();
}
);
}
}
function Server() {
const socket = dgram.createSocket('udp4'); // 创建一个 socket 提供服务
socket.on('message', function (msg) {
process.stdout.write(msg.toString());
});
socket.on('listening', function () {
console.log('Server ready:', socket.address());
});
socket.bind(port);
}
if (process.argv[2] === 'client') { // 根据命令行选项确定运行客户端还是服务端
new Client(process.argv[3]);
} else {
new Server();
}
HTTP 客户端
使用 http.createServer 和 http.createClient 运行 HTTP 服务。
启动与测试 HTTP
const assert = require('assert');
const http = require('http');
const server = http.createServer(function(req, res) {
res.writeHead(200, { 'Content-Type': 'text/plain' }); // 写入基于文本的响应头
res.write('Hello, world.'); // 发送消息回客户端
res.end();
});
server.listen(8000, function() {
console.log('Listening on port 8000');
});
const req = http.request({ port: 8000}, function(res) { // 创建请求
console.log('HTTP headers:', res.headers);
res.on('data', function(data) { // 给 data 事件创建监听,确保和期望值一致
console.log('Body:', data.toString());
assert.equal('Hello, world.', data.toString());
assert.equal(200, res.statusCode);
server.unref();
console.log('测试完成');
});
});
req.end();
重定向
HTTP 标准定义了标识重定向发生时的状态码,它也指出了客户端应该检查无限循环。
- 300:多重选择
- 301:永久移动到新位置
- 302:找到重定向跳转
- 303:参见其他信息
- 304:没有改动
- 305:使用代理
- 307:临时重定向
const http = require('http');
const https = require('https');
const url = require('url'); // 有很多接续 URLs 的方法
// 构造函数被用来创建一个对象来构成请求对象的声明周期
function Request() {
this.maxRedirects = 10;
this.redirects = 0;
}
Request.prototype.get = function(href, callback) {
const uri = url.parse(href); // 解析 URLs 成为 Node http 模块使用的格式,确定是否使用 HTTPS
const options = { host: uri.host, path: uri.path };
const httpGet = uri.protocol === 'http:' ? http.get : https.get;
console.log('GET:', href);
function processResponse(response) {
if (response.statusCode >= 300 && response.statusCode < 400) { // 检查状态码是否在 HTTP 重定向范围
if (this.redirects >= this.maxRedirects) {
this.error = new Error('Too many redirects for: ' + href);
} else {
this.redirects++; // 重定向计数自增
href = url.resolve(options.host, response.headers.location); // 使用 url.resolve 确保相对路径的 URLs 转换为绝对路径 URLs
return this.get(href, callback);
}
}
response.url = href;
response.redirects = this.redirects;
console.log('Redirected:', href);
function end() {
console.log('Connection ended');
callback(this.error, response);
}
response.on('data', function(data) {
console.log('Got data, length:', data.length);
});
response.on('end', end.bind(this)); // 绑定回调到 Request 实例,确保能拿到实例属性
}
httpGet(options, processResponse.bind(this))
.on('error', function(err) {
callback(err);
});
};
const request = new Request();
request.get('http://google.com/', function(err, res) {
if (err) {
console.error(err);
} else {
console.log(`
Fetched URL: ${res.url} with ${res.redirects} redirects
`);
process.exit();
}
});
HTTP 代理
- ISP 使用透明代理使网络更加高效
- 使用缓存代理服务器减少宽带
- Web 应用程序的 DevOps 利用他们提升应用程序性能
const http = require('http');
const url = require('url');
http.createServer(function(req, res) {
console.log('start request:', req.url);
const options = url.parse(req.url);
console.log(options);
options.headers = req.headers;
const proxyRequest = http.request(options, function(proxyResponse) { // 创建请求来复制原始的请求
proxyResponse.on('data', function(chunk) { // 监听数据,返回给浏览器
console.log('proxyResponse length:', chunk.length);
res.write(chunk, 'binary');
});
proxyResponse.on('end', function() { // 追踪代理请求完成
console.log('proxied request ended');
res.end();
});
res.writeHead(proxyResponse.statusCode, proxyResponse.headers); // 发送头部信息给服务器
});
req.on('data', function(chunk) { // 捕获从浏览器发送到服务器的数据
console.log('in request length:', chunk.length);
proxyRequest.write(chunk, 'binary');
});
req.on('end', function() { // 追踪原始的请求什么时候结束
console.log('original request ended');
proxyRequest.end();
});
}).listen(8888); // 监听来自本地浏览器的连接
封装 request-promise
const https = require('https');
const promisify = require('util').promisify;
https.get[promisify.custom] = function getAsync(options) {
return new Promise((resolve, reject) => {
https.get(options, (response) => {
response.end = new Promise((resolve) => response.on('end', resolve));
resolve(response);
}).on('error', reject);
});
};
const rp = promisify(https.get);
(async () => {
const res = await rp('https://jsonmock.hackerrank.com/api/movies/search/?Title=Spiderman&page=1');
let body = '';
res.on('data', (chunk) => body += chunk);
await res.end;
console.log(body);
})();
DNS 请求
使用 dns 模块创建 DNS 请求。
- A:
dns.resolve,A 记录存储 IP 地址 - TXT:
dns.resulveTxt,文本值可以用于在 DNS 上构建其他服务 - SRV:
dns.resolveSrv,服务记录定义服务的定位数据,通常包含主机名和端口号 - NS:
dns.resolveNs,指定域名服务器 - CNAME:
dns.resolveCname,相关的域名记录,设置为域名而不是 IP 地址
const dns = require('dns');
dns.resolve('www.chenng.cn', function (err, addresses) {
if (err) {
console.error(err);
}
console.log('Addresses:', addresses);
});
crypto 库加密解密
const crypto = require('crypto')
function aesEncrypt(data, key = 'key') {
const cipher = crypto.createCipher('aes192', key)
let crypted = cipher.update(data, 'utf8', 'hex')
crypted += cipher.final('hex')
return crypted
}
function aesDecrypt(encrypted, key = 'key') {
const decipher = crypto.createDecipher('aes192', key)
let decrypted = decipher.update(encrypted, 'hex', 'utf8')
decrypted += decipher.final('utf8')
return decrypted
}
发起 HTTP 请求的方法
- HTTP 标准库
- 无需安装外部依赖
- 需要以块为单位接受数据,自己监听 end 事件
- HTTP 和 HTTPS 是两个模块,需要区分使用
- Request 库
- 使用方便
- 有 promise 版本
request-promise - Axios
- 既可以用在浏览器又可以用在 NodeJS
- 可以使用 axios.all 并发多个请求
- SuperAgent
- 可以链式使用
- node-fetch
- 浏览器的 fetch 移植过来的
子进程
基本概念
- 4个异步方法:exec、execFile、fork、spawn
- Node
- fork:想将一个 Node 进程作为一个独立的进程来运行的时候使用,是的计算处理和文件描述器脱离 Node 主进程
- 非 Node
- spawn:处理一些会有很多子进程 I/O 时、进程会有大量输出时使用
- execFile:只需执行一个外部程序的时候使用,执行速度快,处理用户输入相对安全
- exec:想直接访问线程的 shell 命令时使用,一定要注意用户输入
- 3个同步方法:execSync、execFileSync、spawnSync
- 通过 API 创建出来的子进程和父进程没有任何必然联系
execFile
- 会把输出结果缓存好,通过回调返回最后结果或者异常信息
const cp = require('child_process');
cp.execFile('echo', ['hello', 'world'], (err, stdout, stderr) => {
if (err) { console.error(err); }
console.log('stdout: ', stdout);
console.log('stderr: ', stderr);
});
spawn
- 通过流可以使用有大量数据输出的外部应用,节约内存
- 使用流提高数据响应效率
- spawn 方法返回一个 I/O 的流接口
单一任务
const cp = require('child_process');
const child = cp.spawn('echo', ['hello', 'world']);
child.on('error', console.error);
child.stdout.pipe(process.stdout);
child.stderr.pipe(process.stderr);
多任务串联
const cp = require('child_process');
const path = require('path');
const cat = cp.spawn('cat', [path.resolve(__dirname, 'messy.txt')]);
const sort = cp.spawn('sort');
const uniq = cp.spawn('uniq');
cat.stdout.pipe(sort.stdin);
sort.stdout.pipe(uniq.stdin);
uniq.stdout.pipe(process.stdout);
exec
- 只有一个字符串命令
- 和 shell 一模一样
const cp = require('child_process');
cp.exec(`cat ${__dirname}/messy.txt | sort | uniq`, (err, stdout, stderr) => {
console.log(stdout);
});
fork
- fork 方法会开发一个 IPC 通道,不同的 Node 进程进行消息传送
- 一个子进程消耗 30ms 启动时间和 10MB 内存
- 子进程:
process.on('message')、process.send() - 父进程:
child.on('message')、child.send()
父子通信
// parent.js
const cp = require('child_process');
const child = cp.fork('./child', { silent: true });
child.send('monkeys');
child.on('message', function (message) {
console.log('got message from child', message, typeof message);
})
child.stdout.pipe(process.stdout);
setTimeout(function () {
child.disconnect();
}, 3000);
// child.js
process.on('message', function (message) {
console.log('got one', message);
process.send('no pizza');
process.send(1);
process.send({ my: 'object' });
process.send(false);
process.send(null);
});
console.log(process);
常用技巧
退出时杀死所有子进程
- 保留对由 spawn 返回的 ChildProcess 对象的引用,并在退出主进程时将其杀死
const spawn = require('child_process').spawn;
const children = [];
process.on('exit', function () {
console.log('killing', children.length, 'child processes');
children.forEach(function (child) {
child.kill();
});
});
children.push(spawn('/bin/sleep', ['10']));
children.push(spawn('/bin/sleep', ['10']));
children.push(spawn('/bin/sleep', ['10']));
setTimeout(function () { process.exit(0); }, 3000);
Cluster 的理解
- 解决 NodeJS 单进程无法充分利用多核 CPU 问题
- 通过 master-cluster 模式可以使得应用更加健壮
- Cluster 底层是 child_process 模块,除了可以发送普通消息,还可以发送底层对象
TCP、UDP等 - TCP 主进程发送到子进程,子进程能根据消息重建出 TCP 连接,Cluster 可以决定 fork 出合适的硬件资源的子进程数
Node 多线程
单线程问题
- 对 cpu 利用不足
- 某个未捕获的异常可能会导致整个程序的退出
Node 线程
- Node 进程占用了 7 个线程
- Node 中最核心的是 v8 引擎,在 Node 启动后,会创建 v8 的实例,这个实例是多线程的
- 主线程:编译、执行代码
- 编译/优化线程:在主线程执行的时候,可以优化代码
- 分析器线程:记录分析代码运行时间,为 Crankshaft 优化代码执行提供依据
- 垃圾回收的几个线程
- JavaScript 的执行是单线程的,但 Javascript 的宿主环境,无论是 Node 还是浏览器都是多线程的
异步 IO
- Node 中有一些 IO 操作(DNS,FS)和一些 CPU 密集计算(Zlib,Crypto)会启用 Node 的线程池
- 线程池默认大小为 4,可以手动更改线程池默认大小
cluster 多进程
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
// 工作进程可以共享任何 TCP 连接。
// 在本例子中,共享的是 HTTP 服务器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello World');
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}
- 一共有 9 个进程,其中一个主进程,cpu 个数 x cpu 核数 = 2 x 4 = 8 个 子进程
- 无论 child_process 还是 cluster,都不是多线程模型,而是多进程模型
- 应对单线程问题,通常使用多进程的方式来模拟多线程
真 Node 多线程
- Node 10.5.0 的发布,给出了一个实验性质的模块 worker_threads 给 Node 提供真正的多线程能力
- worker_thread 模块中有 4 个对象和 2 个类
- isMainThread: 是否是主线程,源码中是通过 threadId === 0 进行判断的。
- MessagePort: 用于线程之间的通信,继承自 EventEmitter。
- MessageChannel: 用于创建异步、双向通信的通道实例。
- threadId: 线程 ID。
- Worker: 用于在主线程中创建子线程。第一个参数为 filename,表示子线程执行的入口。
- parentPort: 在 worker 线程里是表示父进程的 MessagePort 类型的对象,在主线程里为 null
- workerData: 用于在主进程中向子进程传递数据(data 副本)
const {
isMainThread,
parentPort,
workerData,
threadId,
MessageChannel,
MessagePort,
Worker
} = require('worker_threads');
function mainThread() {
for (let i = 0; i < 5; i++) {
const worker = new Worker(__filename, { workerData: i });
worker.on('exit', code => { console.log(`main: worker stopped with exit code ${code}`); });
worker.on('message', msg => {
console.log(`main: receive ${msg}`);
worker.postMessage(msg + 1);
});
}
}
function workerThread() {
console.log(`worker: workerDate ${workerData}`);
parentPort.on('message', msg => {
console.log(`worker: receive ${msg}`);
}),
parentPort.postMessage(workerData);
}
if (isMainThread) {
mainThread();
} else {
workerThread();
}
线程通信
const assert = require('assert');
const {
Worker,
MessageChannel,
MessagePort,
isMainThread,
parentPort
} = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
const subChannel = new MessageChannel();
worker.postMessage({ hereIsYourPort: subChannel.port1 }, [subChannel.port1]);
subChannel.port2.on('message', (value) => {
console.log('received:', value);
});
} else {
parentPort.once('message', (value) => {
assert(value.hereIsYourPort instanceof MessagePort);
value.hereIsYourPort.postMessage('the worker is sending this');
value.hereIsYourPort.close();
});
}
多进程 vs 多线程
进程是资源分配的最小单位,线程是CPU调度的最小单位